부스팅(Boosting)
배깅은 각 분류기(모델)가 독립적인데 반해, 부스팅은 독립적이지 않다.
부스팅은 이전 모델을 구축한 뒤, 다음 모델을 구축할 때, 이전 분류기에 의해 잘못 분류된 데이터에 더 큰 가중치를 주어
붓스트랩을 구성한다.
약한 모델들을 결합하여 나감으로써, 점차적으로 강한 분류기를 만들어가는 과정
대표적으로 에이다부스팅(AdaBoosting), 그 외에 Gradient Boost, XGBoost, Light GBM 등이 있다.
붓스트랩을 재구성하는 과정에서 잘못 분류된 데이터에 더 큰 가중치를 주어 표본을 추출하기 때문에
훈련오차를 빠르게 줄일 수 있다. 예측 성능 똫나 배깅보다 뛰어나다.
> library(adabag)
> index<-sample(c(1, 2), nrow(iris), replace=T, prob=c(0.7, 0.3))
> train<-iris[index==1, ]
> test<-iris[index==2, ]
> result<-boosting(data=train, Species~., boos=T, mfinal=10)
첫 번째 의사결정 나무

> plot(result$trees[[10]], margin=0.3)
> text(result$trees[[10]])
열 번째 의사결정 나무
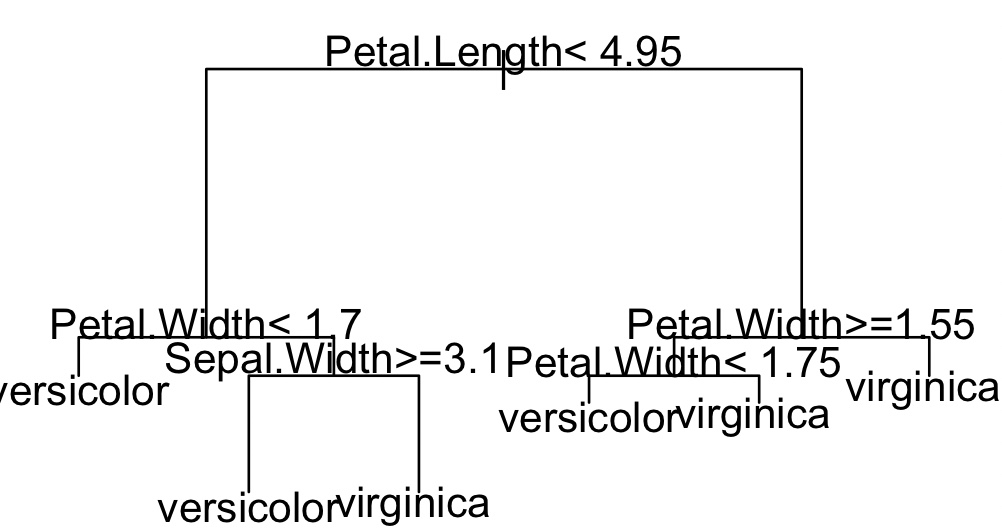
> pred<-predict(result, newdata=test)
> pred$confusion
Observed Class
Predicted Class setosa versicolor virginica
setosa 10 0 0
versicolor 0 14 1
virginica 0 0 10